


Read on to discover how data mesh and fabric revolutionize how organizations handle data, empowering decentralized data ownership and seamless integration across the enterprise landscape.
Introduction
Organizations are increasingly adopting self-service programs to provide the ability to retrieve information, complete transactions, and resolve issues without needing direct assistance. However, the successful implementation of self-service programs heavily relies on effective metadata management. Self-service programs are typically built on digital platforms housing vast amounts of data that must be organized, structured, and easily discoverable. This is where metadata management comes into play. It involves defining, documenting, and maintaining metadata attributes and structures to ensure data is accurately classified, tagged, and labeled. This lets users quickly search, access, and understand the available information.
By establishing a solid link between self-service program implementation and metadata management, organizations can achieve the following benefits:
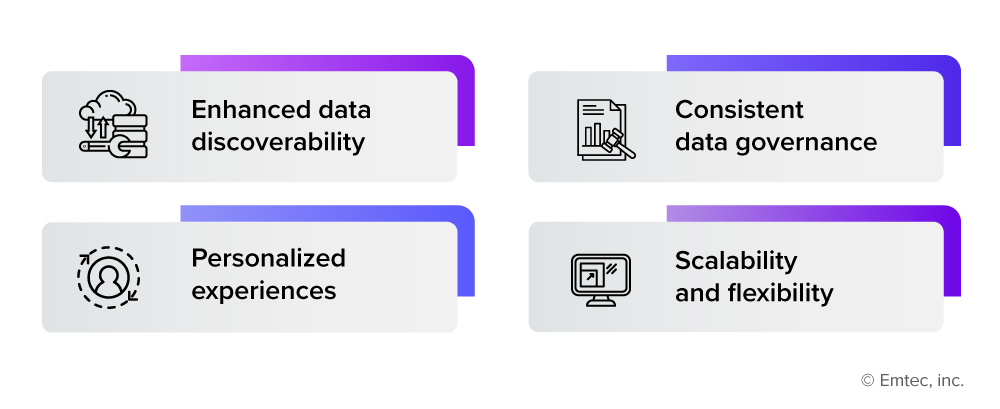
The growing demand for self-service programs which offer decentralized data access is accelerating the transition from conventional data lakes and warehouses to data mesh and data fabric.
Data Fabric and Data Mesh – Enabling Data Democratization and Metadata Management
Data fabric and mesh are cutting-edge data management concepts designed to handle organizational shifts and the complexities associated with:
- Interpreting
- Governing
- Managing organizational data
By 2024, data fabric deployments will quadruple data utilization efficiency along with cutting human-driven data management tasks in half.
What are data mesh and data fabric? Let’s dive into the details:
| What is Data Mesh | What is Data Fabric |
According to Forrester, Data Mesh is a decentralized socio-technical approach for:
|
Gartner defines Data Fabric as an integrated layer of data and connecting processes. |
| Aligns – data sources with data owners classified by business functions or domains. | Enables – development, deployment, and use of integrated and reusable datasets across all environments, i.e., hybrid and multi-cloud platforms. |
Provides – data ownership decentralization to develop data products for:
|
Utilizes – continuous analytics over existing, discoverable, and inferences metadata. |
| Shifts – developing data products for SMEs upstream rather than waiting on cleansing and combining data products downstream. | Facilitates – self-service data consumption at scale and streamlines data access inside an organization. |
| Accelerates – reusing data products by providing a publish-and-subscribe paradigm and leveraging APIs. |
Dismantles – data silos, opening new possibilities for:
|
| Fulfills – the data products needed by data consumers and provides reliable updates. |
Simplifies –
|
Data Fabric vs. Data Mesh – Choose or Co-existence?
Let’s explore how data mesh implementation can be enabled by data fabric architecture and how both paradigms can coexist in an organization through some of the capabilities they offer:
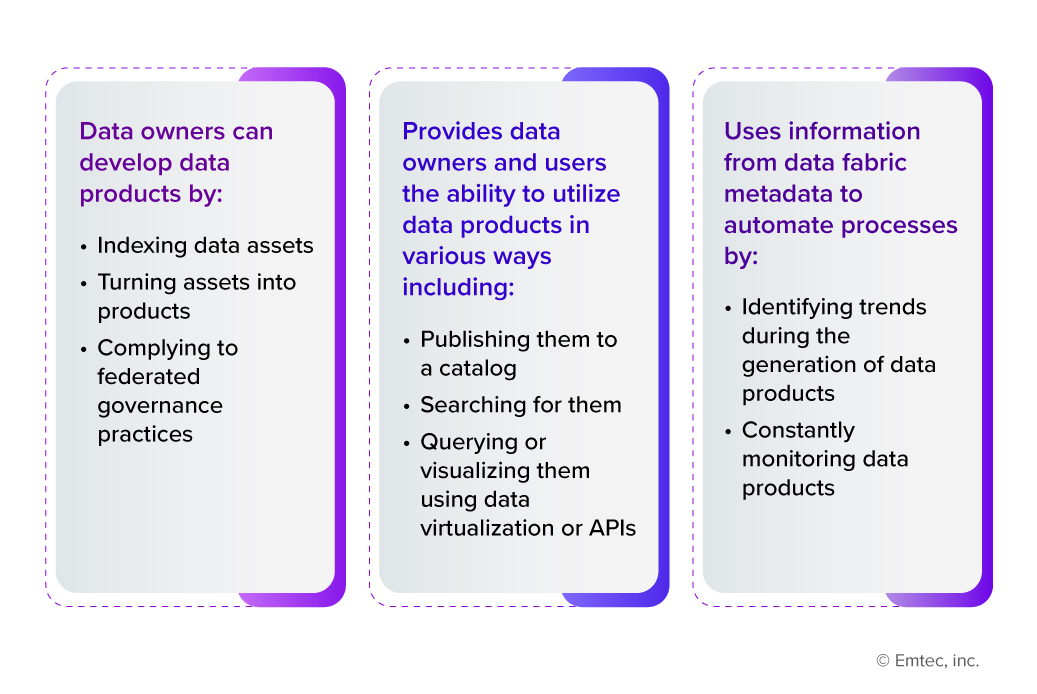
As noted, a data fabric provides critical capabilities to implement and fully utilize a data mesh for data management. It automates many manual tasks to develop data products and manage their lifespans with data observability and quality. This improves time-to-value for data consumers and the productivity of data engineers. Businesses can construct a data mesh while maintaining a use case-centric data architecture by leveraging the flexibility of a data fabric framework, whether the data is on-premises or on the cloud.
Let’s now look at how Snowflake can help implement data mesh.
Snowflake Data Cloud – Empowering Data Mesh
The Snowflake Data Cloud connects organizations and data teams to the data they need whenever required. The Snowflake data mesh approach reduces complexity and data silos, keeping valuable data within reach. Here’s how Snowflake can help your organization reap the benefits of deploying a data mesh architecture:
-
Delivering Secure Self-Service Platforms for Distributed Domain Teams
Actual data ownership is only attainable with the right data platform. Domain teams require on-demand access to resources and technologies to assist them throughout the data product lifecycle. Snowflake provides a comprehensive set of tools for automating data transformation pipelines and producing & managing data products. Snowflake’s platform is built for simplicity and boasts near-zero maintenance and fast resource scaling, allowing users a real self-service experience. Each domain team can deploy and expand its resources based on its requirements, removing the need for an infrastructure team.
-
Data Products – Discovery and Sharing
Snowflake’s platform enables domain teams to function independently while sharing data products. Each domain can choose the data items to share and then publish product descriptions in a Snowflake Data Exchange – a database of all data products in the data mesh. Other teams can search the inventory for data products that satisfy their specifications. Access to data products can be obtained immediately or via a request-and-approval process between the data producer and the user. In either case, users get real-time access to data products without needing ETL or data copying between domains. Each domain can easily track who and how frequently their data items are used.
-
Enabling Federated Governance
Snowflake also has numerous native cross-cloud governance controls required for federated governance. This contains:
- Object dependencies
- Data lineage
- Metadata tags for data products
- Row-level access control
- Dynamic data masking for sensitive information and other restrictions
In Snowflake, defining governance controls like tags or access policies differs from applying these restrictions to data objects. This allows organizations to create common governance standards for the data mesh while allowing specific domain teams to adapt and apply these standards to the data in their domain as they see fit. It helps organizations to adopt federated governance with the proper balance of global standards and domain autonomy.
Partner with Emtec Digital to Implement Data Mesh with Data Governance Practices
If you want to reduce the barriers to implementing a unique self-service data program at scale, then data mesh is the best solution. Emtec Digital can help you leverage your existing data framework by:
- Conducting an in-depth analysis of your current data ecosystem
- Identifying domain teams
- Establishing data product ownership
- Automating data quality monitoring
- Developing cross-functional collaboration
Leverage your data framework to scale data democratization across your organization. Contact our experts today!
References
www.gartner.com/smarterwithgartner/data-fabric-architecture-is-key-to-modernizing-data-management-and-integration
www.forrester.com/blogs/exposing-the-data-mesh-blind-side/
www.theregister.com/2022/10/19/gartern_sees_enterprise_it_as/
https://emtemp.gcom.cloud/ngw/globalassets/en/publications/documents/understand_the_role_of_data_fabric_ebook.pdf
Author
Emtec Digital Think Tank
We are an enthusiastic group of technologists, market and trend analysts, digital evangelists, and subject matter experts. We discuss and share our thoughts on digital enablement, business strategies, customer/market insights, and advanced technologies that help organizations improve operational efficiency and boost revenue.


